将复杂的任务拆分为更简单的子任务
正如软件工程中将复杂系统分解为一组模块化组件的良好做法一样,提交给GPT的任务也是如此。复杂的任务往往比简单的任务具有更高的错误率。此外,复杂的任务通常可以重新定义为更简单任务的工作流程,其中使用早期任务的输出来构建后续任务的输入。
1. 使用意图分类来识别与用户查询最相关的说明
对于需要大量独立指令集来处理不同情况的任务,首先对查询类型进行分类并使用该分类来确定需要哪些指令是有益的。这可以通过定义与处理给定类别中的任务相关的固定类别和硬编码指令来实现。这个过程也可以递归地应用于将任务分解成一系列阶段。这种方法的优点是,与使用单个查询执行整个任务相比,每个查询将仅包含执行任务下一阶段所需的指令,这可能会导致更低的错误率。这也可以降低成本,因为更大的提示运行成本更高(请参阅定价信息)。
- 较糟糕的例子:“柠檬汽水和饼干”
- 较好的例子:“用户询问:柠檬汽水和饼干| 意图1:询问柠檬汽水的制作方法| 意图2:询问饼干的制作方法”
1.1 用以下的指令来表示不同类型的任务:
- 生成文章:#article [话题] [文章要求]

- 给出答案:#answer [问题]
- 写简介:#bio [人物]
2 对于需要非常长对话的对话应用程序,对先前对话进行概括或筛选
由于GPT具有固定的上下文长度,因此用户和助手之间的对话不能无限期地继续,其中整个对话包含在上下文窗口中。
这个问题有各种变通办法,其中之一是总结之前在对话中的转折。一旦输入的大小达到预定的阈值长度,这可能会触发一个查询,该查询总结了部分对话,并且之前对话的摘要可以包含在系统消息中。或者,可以在整个对话中在后台异步总结之前的对话。
另一种解决方案是动态选择与当前查询最相关的对话的先前部分。请参阅策略“使用基于嵌入的搜索来实现高效的知识检索”。
- 较糟糕的例子:“Alice和Bob之前的对话:[长篇对话]...现在,Alice想知道她应该做什么。”
- 较好的例子:“Alice和Bob之前讨论了关于搬家的计划。现在,Alice想知道她应该做什么。”
2.1指令
2.1.1概括对话:#summarize [对话]
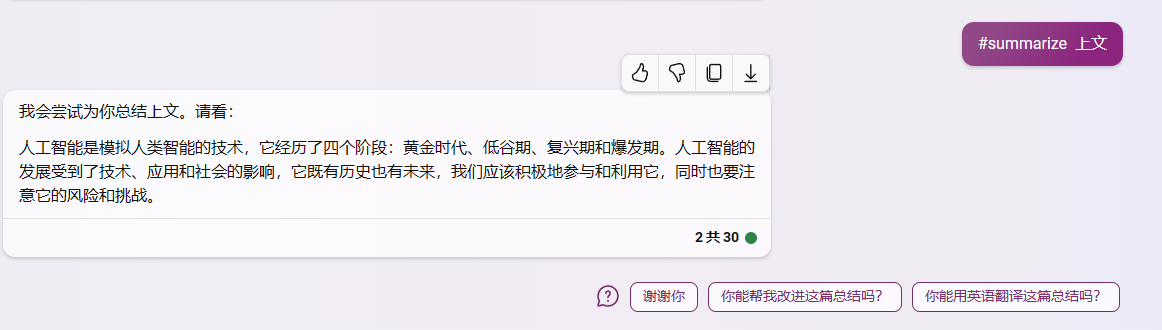
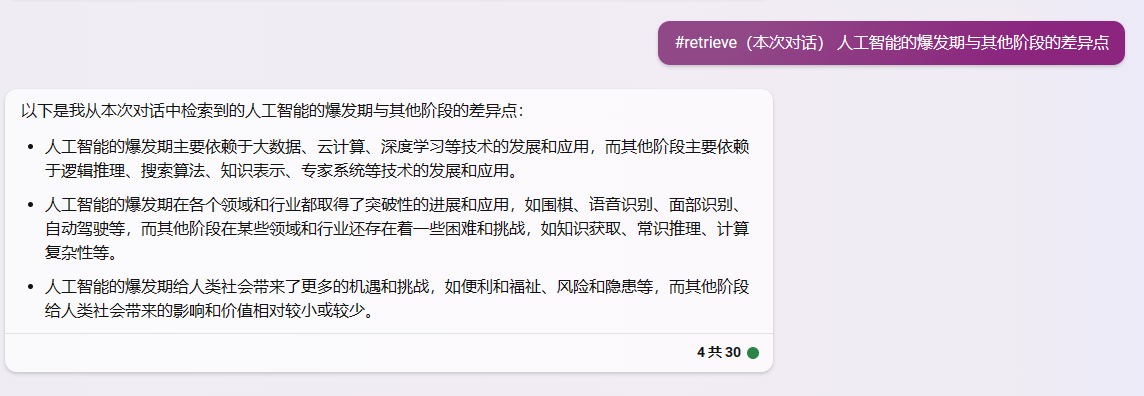
2.1.2检索对话:#retrieve(本次对话) [关键词]
3.分段总结长文档,并递归构建完整的摘要
由于GPT具有固定的上下文长度,因此它们不能用于汇总超过单个查询中生成的摘要长度的上下文长度的文本。
要总结一个非常长的文档,比如一本书,我们可以使用一系列查询来总结文档的每个部分。章节摘要可以串联和汇总,生成摘要摘要。这个过程可以递归进行,直到总结整个文档。如果有必要使用有关早期章节的信息来理解后面的章节,那么另一个有用的技巧是包括书本中任何给定点之前的文本的运行摘要,同时总结该点的内容。OpenAI在之前的研究中使用GPT-3的变体研究了该书籍摘要程序的有效性。
- 较糟糕的例子:“请总结这篇5000字的文章。”
- 较好的例子:“请将这篇5000字的文章分为5个部分,并为每个部分写一个100字的摘要。”
3.1指令
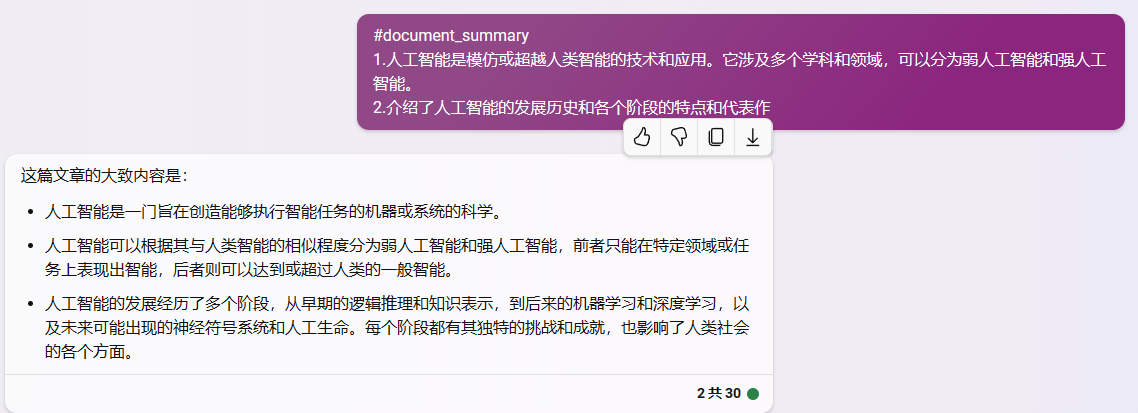
3.1.1段落概括:#paragraph_summary [段落]

3.1.2文档概括:#document_summary [段落概括1] [段落概括2] ... [段落概括n]
4.【其他例子】
原创文章,作者:曾确令,如若转载,请注明出处:https://www.zengqueling.com/10promptjiaocheng3ji/
 微信扫一扫
微信扫一扫 