使用外部工具
通过向GPT提供其他工具的输出来补偿GPT的弱点。例如,文本检索系统可以告诉GPT相关文档。代码执行引擎可以帮助GPT进行数学和运行代码。如果一项任务可以通过工具而不是GPT更可靠或高效地完成,请卸载它以充分利用两者。
使用基于嵌入的搜索来实现高效的知识检索
如果作为其输入的一部分提供,模型可以利用外部信息来源。这可以帮助模型产生更明智和最新的响应。例如,如果用户询问有关特定电影的问题,则在模型的输入中添加有关电影的高质量信息(例如演员、导演等)可能是有用的。嵌入可用于实现高效的知识检索,以便在运行时动态地将相关信息添加到模型输入中。
文本嵌入是一种可以测量文本字符串之间相关性的向量。类似或相关的字符串将比不相关的字符串更紧密地结合在一起。这一事实,加上快速矢量搜索算法的存在,意味着嵌入可用于实现高效的知识检索。特别是,文本语料库可以拆分为块,每个块都可以嵌入和存储。然后可以嵌入给定的查询,并可以执行矢量搜索,以找到与查询最相关的语料库中嵌入文本块(即在嵌入空间中最接近的文本块)。
实现示例可以在OpenAI食谱中找到。有关如何使用知识检索来尽量减少模型构成不正确事实的可能性的示例,请参阅策略“指示模型使用检索到的知识来回答查询”。
-
较糟糕的例子:“《星际穿越》主演之间是什么样的人物关系?”
如果脱离了我们检索的上下文,GPT4的回复很有可能会超出影片主演的范围,导致回答准确性大幅下降。比如,脱离上下文直接询问,回复中甚至掺入了配音演员
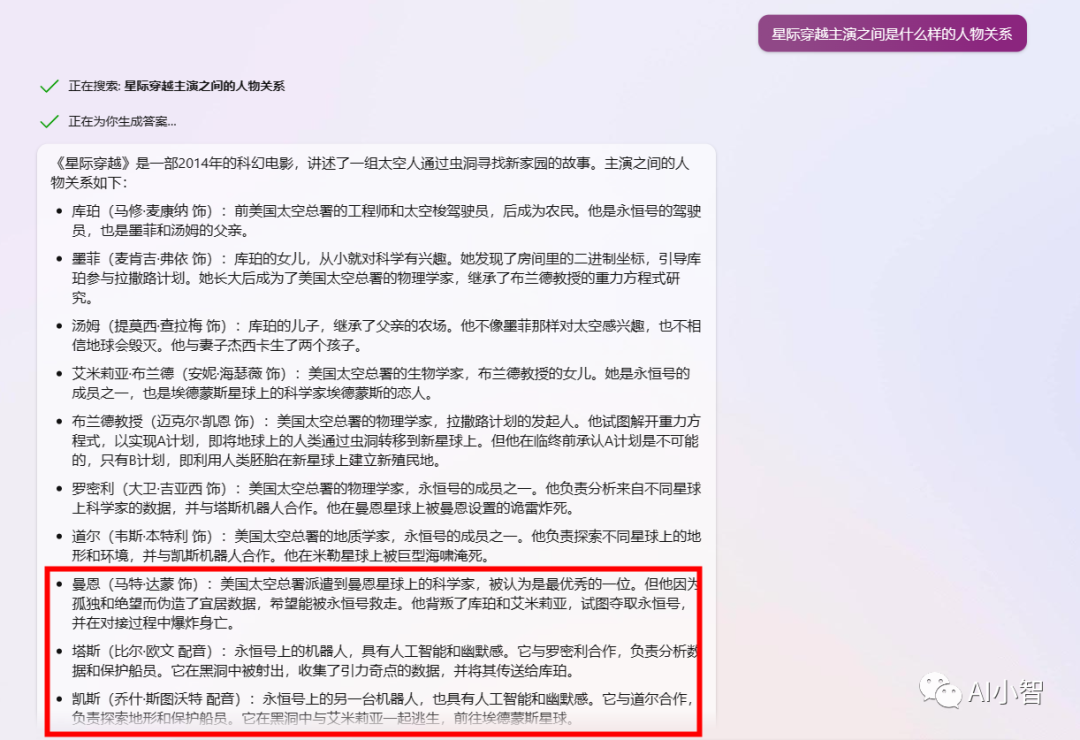

- 较好的例子:“使用基于嵌入的搜索,在这些资源中找到《星际穿越》主演之间是什么样的人物关系?”
使用代码执行来执行更准确的计算或调用外部API
不能依靠GPT自己准确执行算术或长计算。在需要的情况下,可以指示模型编写和运行代码,而不是自己进行计算。特别是,可以指示模型将旨在运行的代码放入指定格式,如三重背景。产生输出后,可以提取代码并运行。最后,如有必要,代码执行引擎的输出(即Python解释器)可以作为下一个查询的模型输入。
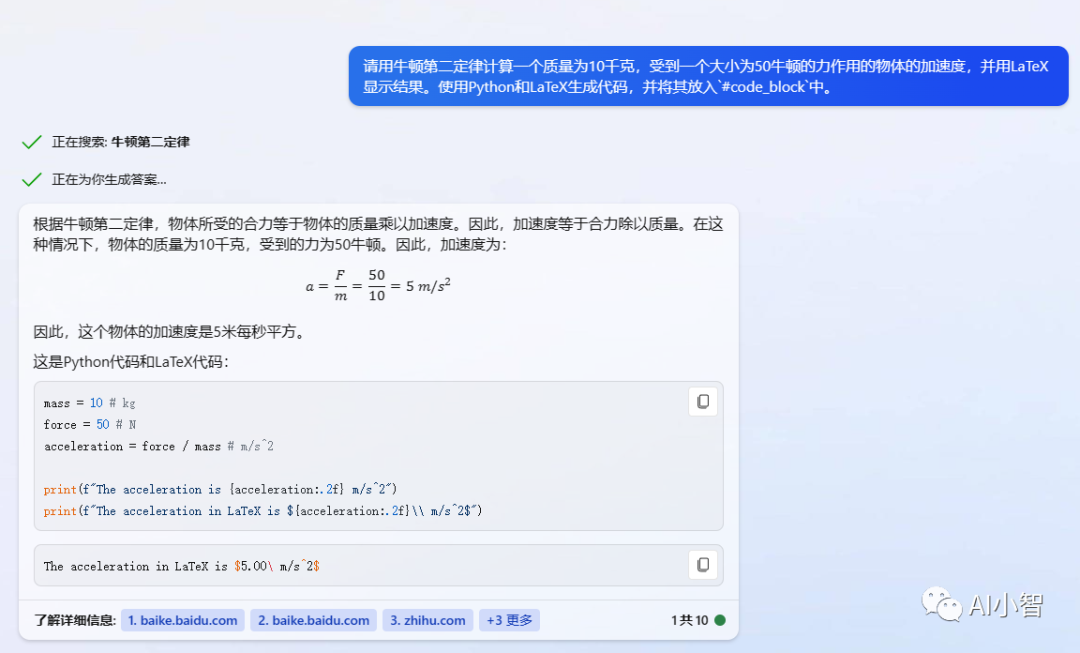
- 较糟糕的例子:“请用牛顿第二定律计算一个质量为10千克,受到一个大小为50牛顿的力作用的物体的加速度。”
-
较好的例子:“请用牛顿第二定律计算一个质量为10千克,受到一个大小为50牛顿的力作用的物体的加速度,并用LaTeX显示结果。使用Python和LaTeX生成代码,并将其放入 #代码 中。”
- #markdown 格式
- #markdown 格式
原创文章,作者:曾确令,如若转载,请注明出处:https://www.zengqueling.com/10promptjiaocheng5sh/
 微信扫一扫
微信扫一扫 