GPT的原理[一句话:大力出奇迹 ]
1.实质功能:自回归生成
单字生成:根据上文,生成下一个字。
把自己生成的字和原文组合成为上文,再生成下一个字。
输入大量的文本,人类的几千年文化沉淀。
对于同样的上文,生成概率分布。
实际上 ChatGPT 给出的结果长这样,也就是「所有字的概率分布」,「生成的下一个字」就是按照概率分布抽样得到的结果。
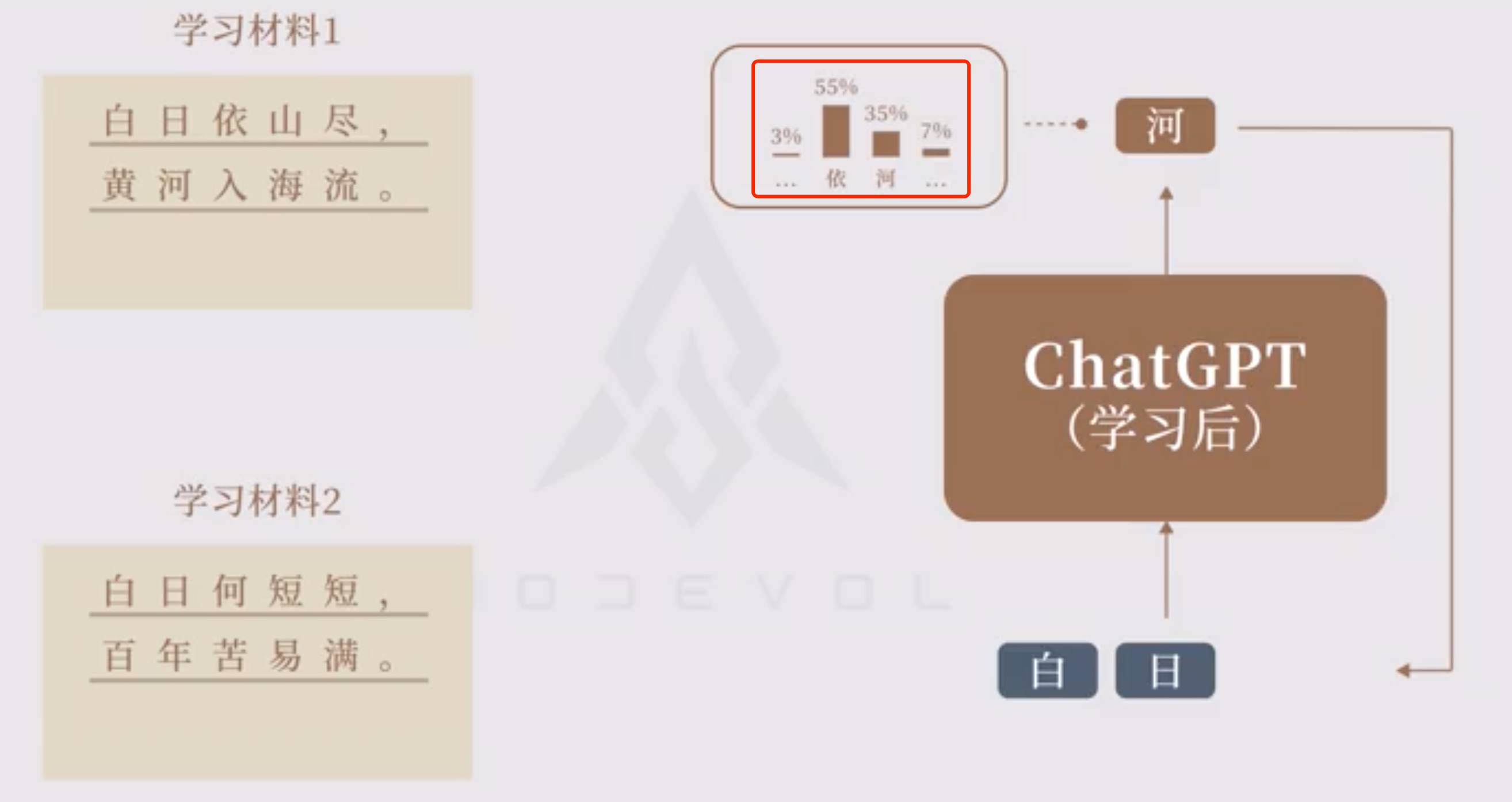
由于抽样结果具有随机性,所以 ChatGPT 的回答并不是每次都一样。
把问题和答案组成范例,然后再输入到模型里面。
2.泛化:预训练
自回归生成的过程可以让模型学习通用规律。
这是因为,当大量的各类文本输入后,问题和回答的通用规律的出现次数远高于某个知识点的范例,就会成为最高级别的生成概率。
这一点就和搜索引擎不同,不是去找答案,而是留下人类文化中的精华文字上下文的模板。
输入大量数据,不是为了记忆,而是调整模型,得出通用模型。
2.1参数
各种语言模式和上下文关系,并将这些模式和关系编码成为模型的参数。
这些参数可以被看作是模型对自然语言的理解和表达的基础,它们包含了GPT模型所学习到的语言知识的总和。
类似在大量的阅读中,自然掌握了英语语法:各种时态,主谓宾结构,定语从句等


2.2长处:
因此,即使未到数据库记录记忆的情况,也可以根据通用模型而进行生成结果。
所以,chatgpt称为[生成模型],也会创造不存在的文字。
2.3短板:
- 胡说八道
- 实际上不同,但碰巧遇到统一规律。
- 也就是现实中不存在的内容,chatgpt就会对其进行[合乎规律的凭空捏造]。
2.4无法对模型中的内容,进行增删改查。
1. 我们很难理解它所构建的规律,也无法查看它记住了什么,学到了什么。它的模型暂时缺乏可解析性。
2. 为了改变这种胡说八道的情况,只能对胡说八道的内容再次大量训练正确的回答,这样效率就降低了。2.5高度依赖数据
* 想要好的结果,必须要大量,种类多,质量好的数据。
* 学习的材料非常重要。原创文章,作者:曾确令,如若转载,请注明出处:https://www.zengqueling.com/8gptdeyuanli/
 微信扫一扫
微信扫一扫 