很多人都见过这段话吧:


这是认知心理学中关于单词和阅读的一个经典发现,叫做 typoglycemia。
我心生好奇:对 GPT 来说,满是 typo 的英文句子,它能像人一样不受影响正常读懂吗?
咱们来试一试。
我找了个错字连篇的英文版本喂给 chatgpt。它读懂了,告诉我“部分同意”,还 blabla 说了一大堆理由。
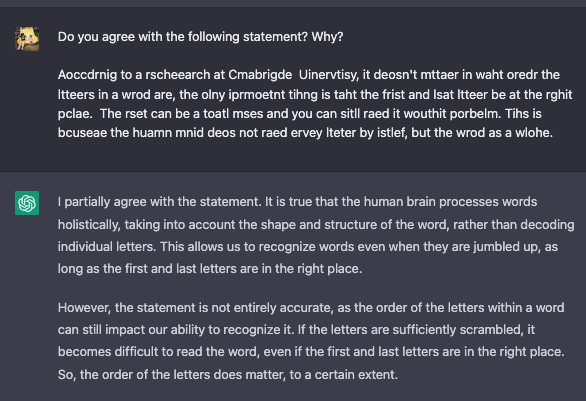
再换中文问它(我懒得自己编,为了节约点语料给后面用,就只复制了英文版本的第一句话),它还是读懂了,但竟然说不同意。

换个方法来问,它还是能读懂,但也还是坚持认为句子的意思很重要。

最后一句话。这回它竟然赞同了,而且说得比英文原文更清楚明白。(还补充说“研究表明”,你哪里看来的研究啊!)
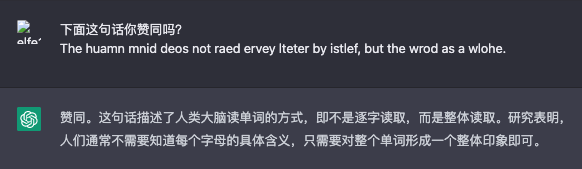
这时我才意识到光拿第一句话问它属于断章取义。整段连起来它赞同,光取第一句话它依旧不认可。

为了进一步验证,我生造了一句全是错别字的问题,问它橙色和蓝色哪个感觉更暖和。它完全忽略拼写错误,读懂了问题,并认真给我讲解了颜色冷暖的知识。

Typoglycemia 现象的关键要素在于单词虽然拼写错误,但首尾字符是对的。我尝试着让首尾字符错误(但别的位置的字母正确的更多一些)。你猜怎么着?ChatGPT 像人类一样抓瞎了!直到最后一次尝试,只有少数词瞎拼,它才明白了一半。
换其它语言的首尾字符正确的版本尝试,先不管它的观点是啥,至少除了冰岛语,其它它都读懂了。


本次实验结论:对于满是拼写错误的句子,ChatGPT 表现出了和人类相似的认知能力。 人类能懂的它也能懂,人看不懂的它也不懂。
神奇。心理学书上说,人类这个表现是因为我们有一定的知觉广度,重点关注外周线索,并会自动对内侧的信息进行加工。可是,ChatGPT 为啥也是这样?难道它也像人一样会挑重点?
简单了解了下,Bert/GPT 等在训练英文等语言的时候最小单位不是单词,而是 BPE。Byte-Pair Encoding, 可以理解为词缀(不是语言学家整理的词缀,而是自动训练得到的)。莫非,首尾字母错,破坏词缀的可能性更大?
这样训练出来的结果和人类大脑有类似的认知表现,真是挺有趣的。
原创文章,作者:曾确令,如若转载,请注明出处:https://www.zengqueling.com/ctjhrlxsdrznl/
 微信扫一扫
微信扫一扫 