ChatGPT 做定性研究的质量怎么样?用定量方法来研究下!附prompt
来源:[AIGC研究社]
ChatGPT 作为语言模型,最擅长的就是文本的理解和处理。这正好是用户研究工作中定性研究所需要的技能。
相信很多人自己也使用过 ChatGPT 来对访谈材料进行总结,对主观题进行分类,但总结和分类的质量怎么样,跟人类比又如何,目前还很少看到响应的定量结论。
最近发现了一篇研究(
https://measuringu.com/classification-agreement-between-ux-researchers-and-chatgpt/),作者对比了3 个人类研究员和 3 次 ChatGPT 产出的一致性,以此来对比 ChatGPT 跟人类相比,处理定性材料的结果怎么样。
以下是详细介绍。
研究目的
比较 ChatGPT 和人类 UX 研究员在对用户评论进行主题分类时的一致性,以了解 ChatGPT 在此任务上的优势和缺陷。
方法
- 收集 3 个 UX 调研项目中的大约 50 条参与者对网站问题的原始反馈语句。
- 3 名人类编码员分别对每条语句分类成不同主题。
- 要求 ChatGPT 对同样的语句产出 3 次分类
- 比较人类编码员与 ChatGPT 在产生的主题数量及语句分类的一致性。
结果:
- 在包含单语句的主题方面,人类编码员平均产生2倍于 ChatGPT 的主题数量。
- 删除单语句主题后,人类和 ChatGPT 产生的主题数量类似。
- 根据语句覆盖情况匹配主题时,同一主题的命名存在细微差异。
- 根据语句分类的一致性,不管人类间、ChatGPT 间还是人类与 ChatGPT 之间,百分一致性、kappa值 均显示出高度一致。
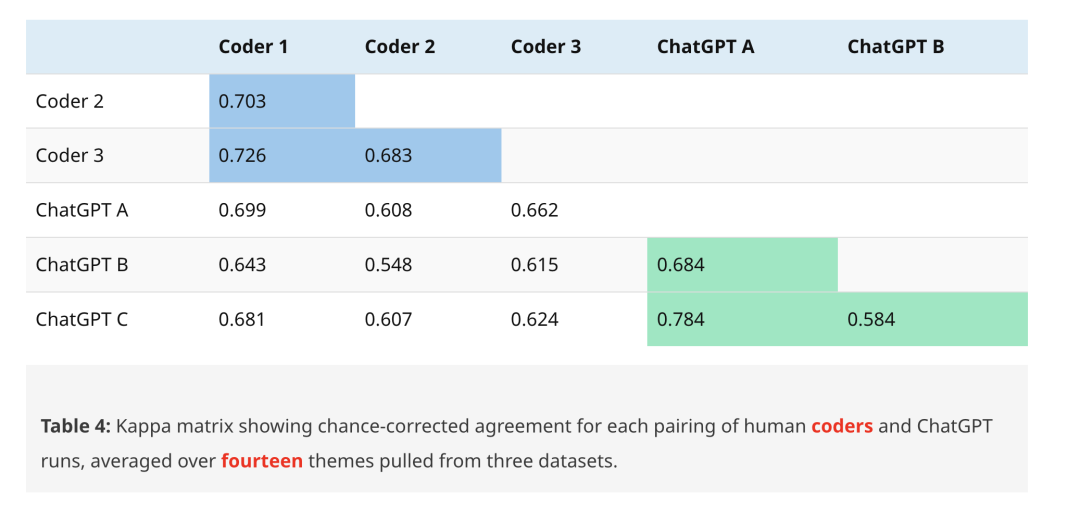

可以看到,ChatGPT 产出的结果与人类研究员的结果是高度一致的。以后在面临大量的主观题分类任务时,我们至少是可以相信 ChatGPT 的。
需要注意的是,ChatGPT 产出高度依赖 prompt,以下是作者的原始 prompt
作为UX研究员,您的任务是分析下面提供的数据集,其中包含对问题“您在XXXX网站上遇到过哪些问题或不满意?”的回答。您的目标是根据常见主题对每个编号的陈述进行分类。按需要创建尽可能多的类别,将相似的陈述分组。如果一个陈述适用于多个类别,请在所有相关的类别中包含它。开始数据集:[参与者编号的数据集] 结束数据集
分析完数据集后,请按以下步骤执行:列出您创建的类别,并为每个类别提供简要描述。对于每个类别,列出属于该类别的陈述的编号。如果有任何陈述不适用于您创建的任何类别,请分别列出它们的编号。
额外知识点:kappa 值
作者在文中使用了一个我不熟悉的一致性的衡量指标:Kappa 值,找了一些相关的材料,一起学习
Kappa 统计量(Kappa statistic)是一种用于衡量分类器性能的统计指标,它主要应用于衡量两个或多个评估者(raters)对同一组对象进行分类时的一致性。Kappa值的范围通常在-1到1之间。
Kappa值的计算方法如下:
- 创建一个混淆矩阵(confusion matrix),该矩阵记录了不同评估者对于每个类别的分类结果。
- 计算每个评估者的分类准确率(accuracy),即对角线上的值与所有值之和的比值。
- 计算随机分类器的期望分类准确率,即每个类别的随机概率乘以每个评估者的分类准确率,然后将所有类别的结果相加。
- 计算Kappa值:$kappa = frac{observed accuracy - expected accuracy}{1 - expected accuracy}$。
在实际应用中,Kappa值可以帮助我们了解分类器的性能。例如,在医学影像诊断中,可以使用Kappa统计量来评估不同放射科医生对同一组影像的诊断结果的一致性。
如果你对这篇文章感兴趣,而且你想要了解更多关于AI领域的实战技巧,可以关注「 AIGC研究社 」。在这里,你可以看到最新最热的AIGC领域的干货文章和案例实战教程。
加入技术交流群d1878810988
跟大家推荐下几个AI工具,免费的:
一品AI助手(免费ChatGPT):http://ai.y-p.cc/chat/
一品AI 文案(免费多场景AI文案):
http://ai.y-p.cc/text/create.html
一品AI画师(免费AI绘画):http://ai.y-p.cc/aiart/
一品AI工具集:http://ai.y-p.cc
原创文章,作者:曾确令,如若转载,请注明出处:https://www.zengqueling.com/czdxyjdzlzmyydlfflyj/
 微信扫一扫
微信扫一扫 