Prompt 到底是什么?
1. 指令
如果把ChatGPT具象成一个执行力&知识广度拉满的 员工 ,那Prompt则是你给的 指令 ,指令越详细,上下文越丰富,输出定义越明确,得到的结果也就越好。
2. 内容
正因为Prompt和输出结果的 强相关性 ,市场对Prompt的价值非常认可。有投机客会发广告直接卖Prompt的bundle,也有Promptbase这样的marketplace交易Prompts。最受欢迎的模式还是把高质量的prompt套一层UI,封装成SaaS产品 (Jasper, CopyAI)。除了那些有自己的独特数据或大模型的公司,这些公司本质上都是在出租 Prompt 来获取价值。
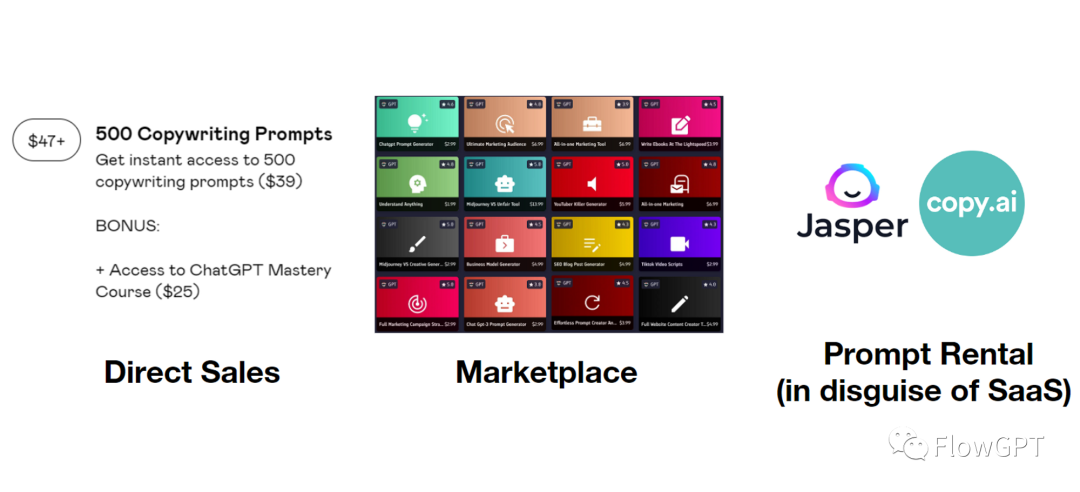
 我们认为Prompt并不是用来出租和出售的商品,而是像短视频和代码一样会被分享和讨论的内容。
我们认为Prompt并不是用来出租和出售的商品,而是像短视频和代码一样会被分享和讨论的内容。
ChatGPT爆火后,市场对Prompt的认知快速提升,各个细分领域的的Influencers分享了大量免费好用的Prompt,由于创作门槛本身就低,越来越多的人开始参与Prompt创作,Prompt的体量供应爆炸式增长。Japser的用户发现网上随便找的Prompt可以在ChatGPT免费用,即使效果不如Jasper,也都跑去用ChatGPT了。未来市场并不愿意为Prompt付费,因为用户有太多免费的选择,低门槛高多样性的Prompt会成为一种新内容,被分享,consume,和迭代。
3. 下一代的(自然)编程语言
| 代码 | Prompt |
|---|---|
| ------------------------------------------------------- | ------------------------------------------------------- |
| 用强逻辑性结构的抽象语句让计算机操纵服务器/本地的数据 | 用自然语言让大模型操纵服务器/本地以及训练数据集的数据 |
| 用于IT&Software | 用于内容创作 |
Prompt最让我们兴奋的点是它极大降低了用户批量操纵数据的门槛,让任何人都变成了软件工程师, 能给自己搭建信息时代的解决方案。
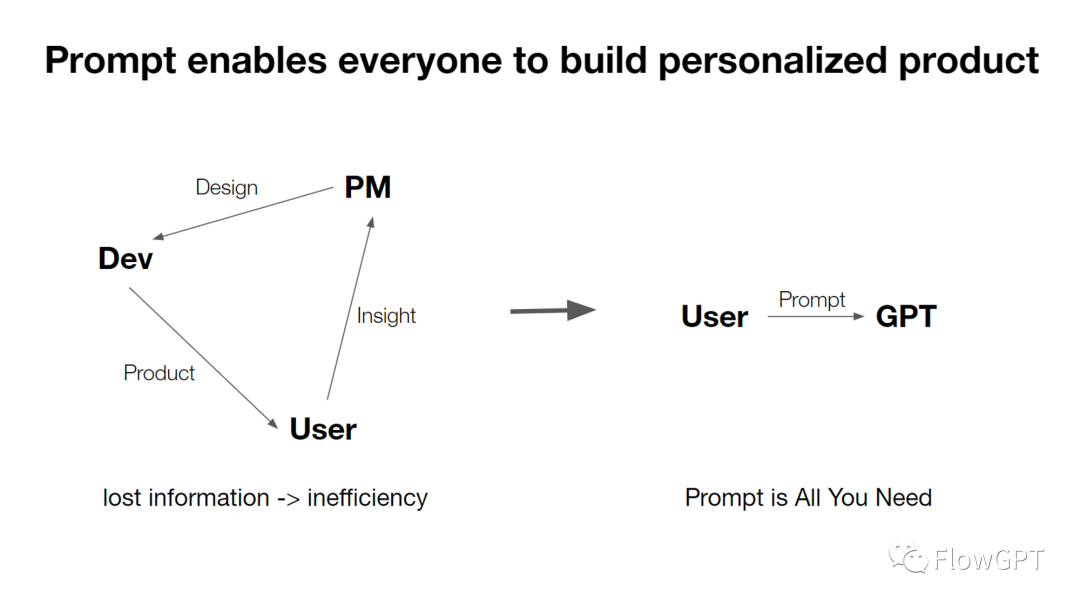
拿软件举例子,代码的创作者是程序员,使用者是终端用户,程序员不知道用户想要什么,所以需要产品经理去了解用户,把他们的需求翻译成产品功再能给程序员实现。这个流程有大量的交流导致的信息损耗,非常低效。而这个流程存在的原因则是终端用户没有时间和技能去写代码做软件。
Prompt的出现彻底改变了这一流程,从此以后,只需要用自然语言描述问题和相应的步骤,就可以搭建个性化的解决方案,省去了让一个专门的团队来找问题迭代产品PMF的步骤,因为用户自己是最好的产品经理。
Prompt相比代码有着极低的创作门槛,更强大的能力,更多的使用场景,因此更大的体量。
4. 产品想象力的载体
过去人们想要创作需要想象力,专业技能和时间。比如想写一个故事,得先构思想象一下故事内容,再用写作技能实现。或者做一个 App ,要先设想功能、界面,然后用设计和编程技能将其实现。这可能需要一个人或一个团队。问题在于培养这些技能的周期很长,花费也很大,因此才会有分工。
然而,生成式模型的出现使任何人都具备了行业专家级别的技能。实现任何想法,只需用 prompt 描述,就能迅速实现和迭代。Prompt 成为了想象力的载体。
在GPT出现之前,沉淀想象力没有任何意义,因为只有最终实现的成品才会有人使用或浏览,所以我们看到的都是像App Store, YouTube, Spotify这样沉淀成品的平台。现在,想象力就是成品。
Prompt Engineering的最终形态是对大模型使用场景的探索。目前我们面临的一个非常现实的问题是大家不知道 AI 能用来干什么。举个例子,在听到 HustleGPT(让 ChatGPT 当老板帮你赚钱)之前,我们完全没有意识到 ChatGPT 还能这么用。包括每天在 FlowGPT 上看大家上传的各种各样 Prompts 时,都会被大家的想象力震惊,以前根本没有想到这样的使用场景。
5. AI原生应用的最简形态
Prompt会怎么发展?
1. 更复杂
Prompts会变得更复杂来完成越来越复杂和细分的任务。这一次更新 ChatGPT 到 GPT-4 之后,我们和很多社群的成员沟通过,做了非常多的观察。发现 GPT-4 的 prompt 普遍是比 ChatGPT 的 Prompt 要更复杂、更长。
我们可以拿代码做一个类比,代码早期没有什么高阶的编程语言,用 Python 能一行写完的逻辑,那个时候的代码需要十几行,同时电脑(代码的载体)在内存、在显示上的能力也非常有限,所以早期的软件相比今天非常简陋。但随着越来越高级的编程语言和框架的出现, 以及硬件性能的提升。软件的复杂度、能解决的问题是越来越多的,才有现在的互联网软件时代。
同样的变革正发生在 Prompt 上。GPT-4 有着 更强的对自然语言的理解能力 ,意味着 ChatGPT 需要十几句话才能讲明白的逻辑,在 GPT-4 里面一句话就可以讲明白。prompt 工程师可以写出更容易被理解、修改、和规模化的 prompt。同时 GPT-4 的缓存也提升了8倍,意味着 Prompt 的复杂度上限也大幅度提升,能解决的问题的复杂度和体量也将迅速扩大。在社群里,ChatGPT的prompts普遍使用场景是改简历,写文案,做策划等简单的模块,GPT4的prompts则包含文字冒险剧本杀游戏,甚至有游戏引擎,prompt编程框架等。
2. 更牛逼
Prompt能力提升来自于大模型本身的升级。比如GPT能联网以后,所有的prompt都被赋予了实时获取讯息和搜索的能力,复杂度又多了一个纬度。ChatGPT Plugin Store也是类似的,Prompt被赋予了能够使用别的SaaS软件来存取数据以及操作的能力。之后能进一步链接思域数据甚至物理世界的能力。Prompt能做的事越变越多了。随着模型本身能力变强,模型种类变多,prompt能够解决的问题体量也迅速增长。
3. 更多元
Prompt是AI原生应用的最简形态, 是一种全新的内容。
我们认为 AIGC 有两种融入产业的形态:
| +AI | AI+ |
|---|---|
| 把之前以软件主导的工作流加上 AIGC 的模块来大幅度降本增效,比如 Notion AI,微软的 Copilot,还有 Adobe 的 Firefly. | 通过多个大模型和 prompt 的协作组成的 AI 原生的工作流。前段时间 Twitter 有一个人用 ChatGPT 加 Midjourney 在一天内创作了一本绘本故事,然后放到亚马逊上卖。这就是一个最简形态的 flow。 |
基于对prompt的进阶控制和能力拓展,会出现各种各样形态的AI原生应用比如把多个prompt连起来的prompt工作流(chain of prompts), 让prompt根据目标生成更多prompt来自动完成任务的自治agents(AutoGPT), 给prompt提供私域数据(vector embeding)的context-aware聊天机器人. 这里举一个prompt工作流的例子.
未来人们做AI+的绘本,只需给一个标题, ChatGPT 的某个 Prompt 就会以此生成故事大纲,而另一个 Prompt 会根据大纲来生成给 Midjourney 用的图片 Prompt , Midjourney 会以此生成一些插画,后面可能会有图生文的大模型,用插画生成了环境描写。最下面是一个多模态大模型,给所有生成的内容排版润色,最后输出一个完整的绘本故事的PDF。
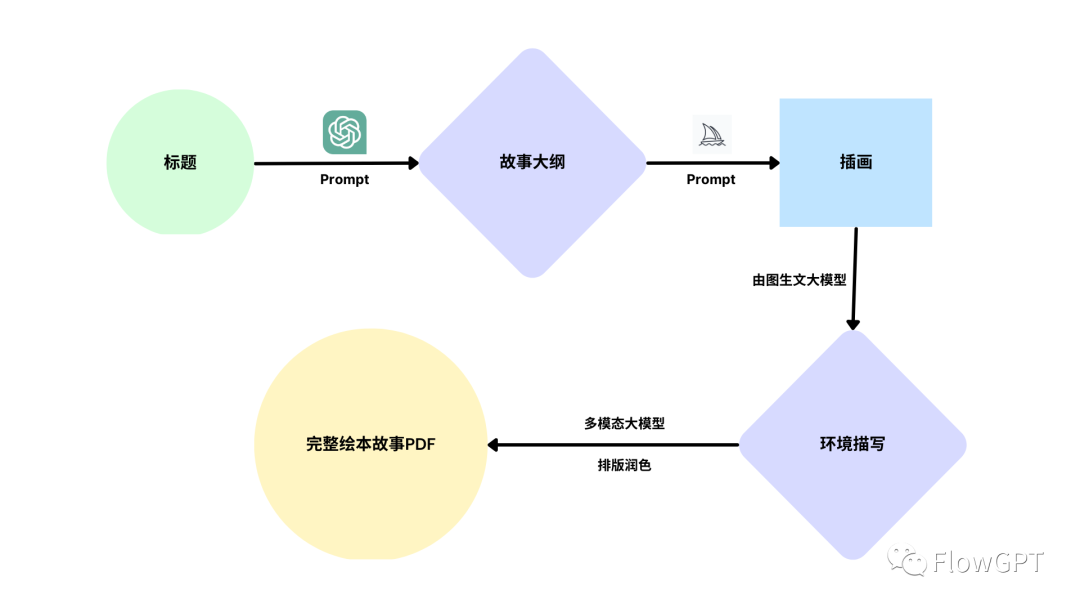
这里面的每一个模块都是一个独特的 「Prompt +大模型」 的一个组合,多个模块之间的协作形成了一个 AI 原生的工作流,也就是一个 flow。要知道这个 Twitter 上的小哥本身是一个软件工程师,他没有任何的插画和写作经验。过去做这件事至少要3个人,他们可能分别会用 word、PS 和 Adobe ,现在你只需要会写 Prompt ,会设计 flow 。这样的Flow未来会越来越多,并且越来越复杂。
Future LLM = Data Monopoly
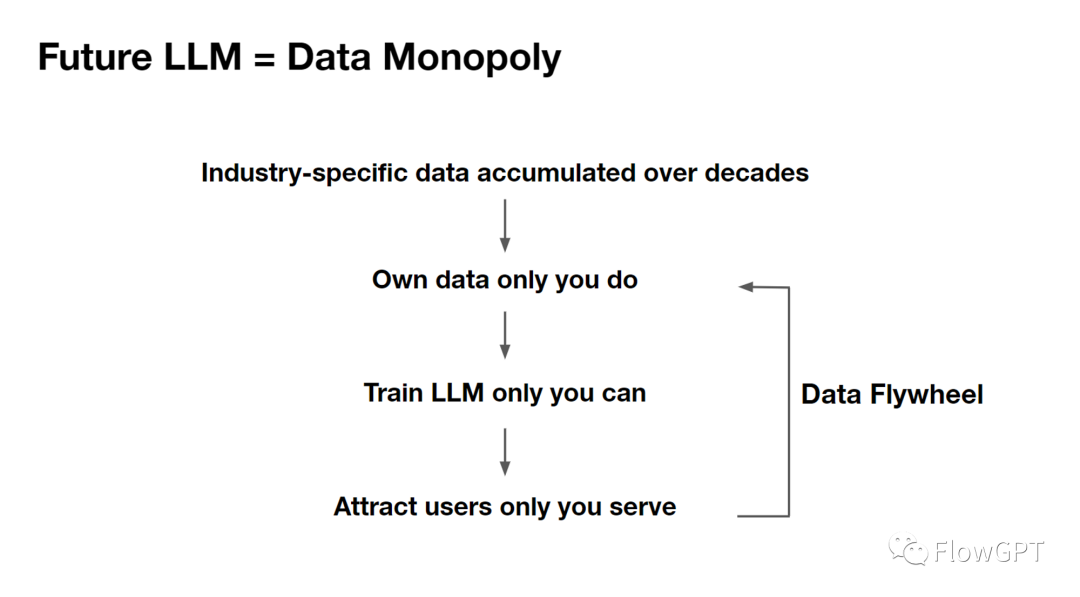
如前几周金融行业的巨头 Bloomberg 用之前积累的金融领域独特数据,训练了一个专用于金融任务的大模型。在金融相关的任务上,能力远超过现有的模型。我们觉得这样的模型会非常快地吸引并留住一部分用户,通过用户的反馈能够不断去迭代模型的能力,再吸引更多用户,形成一个正循环。这就是Sam说的数据飞轮。
我们现在看 OpenAI 能够这么火,成为一个主要的玩家,我觉得有两个原因:
- 第一是有非常好的人才,这些人才有非常好的技术,做出了 GPT-3.5;
- 第二就是有足够的资本,有能力去试验,去训练大模型很多次。但是他们用的数据大部分是网上公开的数据,加上一小部分他们自己雇人去标注RLHF的数据。
但是随着开源的这种大模型的框架慢慢变多,再随着大模型的训练成本迅速降低,其实很快每个人都可以有能力用开源数据训练一个自己的 GPT ,包括现在也已经有很多这样的开源框架能够复现 GPT 一部分的能力了。
那个时候拼的就是谁有别人没有的数据,谁有 数据垄断 。最先意识到这件事的机构可以最先训练出一个特化大模型,就像 BloombergGPT 一样,可以最先去面向用户。此过程中会收集非常多的反馈数据,能够去迭代他自己的大模型,然后搭上一个飞轮,形成非常强的壁垒。
我们其实可以参考神经网络的发展历程。在刚出来的时候,去训练一个在ImageNet达到93%准确率的分类模型需要1000多美元,但现在成本只有几毛钱,这整个过程花了不到10年时间。现在随便一个高中生都会训练神经网络,而缺的是数据。同样的情况会在大模型上出现,它的成本一定会下降。未来训练大模型的成本花费一定不是问题,主要问题一定是有什么别人没有的数据, 有没有数据上的垄断。
原创文章,作者:曾确令,如若转载,请注明出处:https://www.zengqueling.com/wsmwmjxpswl/
 微信扫一扫
微信扫一扫 